The Future of Application Security: Integrating LLMs and AI Agents into Manual Workflows

Introduction
The responsibility of an application security team in any organization has traditionally been to reduce risk. They do that by identifying and remediating security vulnerabilities as early as possible in the Software Development Lifecycle (SDLC). They generally engage with engineering teams to help them implement security controls and eliminate vulnerability classes, where applicable.
Application Security or AppSec engineers tend to start their engagement with engineering teams by invoking some sort of an intake process - whether it is via a ticketing system, a chatbot, or a manual request. The initial phases generally comprises of some sort of a triaging step to understand the scope of the request, the urgency, the priority, and the impact. This is then followed by a series of security activities such as threat modeling, code reviews, dynamic scanning, static analysis, penetration testing, etc. The idea being that the more security activities we can perform early on in the SDLC, the more effective we will be in identifying and remediating vulnerabilities before they can be deployed to production.
This is a critical part of any appsec engineer's job and one that will always be relevant. However, most of the security activities that appsec engineers perform today are manual and repetitive in nature. At least the ones that are performed early in the SDLC - risk classification, risk assessments, threat modeling, design reviews, etc.
These activities are not only manual but also time consuming and not scalable. They are subjective to the skillset of the individual performing them and are more reactive in nature i.e. they are performed only when engineering teams engage with the AppSec team, not vice versa. And, with cost cutting measures being put in place across organizations, it is becoming increasingly difficult to justify the hiring of more appsec engineers. This means that the appsec team is going to have to get more out of the existing team. They have to ruthlessly prioritize what needs to be reviewed because it is impractical to expect an AppSec team to be able to review everything that is being built. This is where LLMs and AI agents can help.
Opportunity with Generative AI (GenAI) and Large Language Models (LLMs)
LLMs are the next big thing in the tech world and they are already changing the way we interact with computers. They are going to change the way we write code, the way we design products, the way we build software, the way we interact with each other, and the way we approach application security.
LLMs are capable of understanding and generating human-like text and this ability to parse complex text and simplify them is going to be a game changer. A lot of the mundane appsec activities that we perform today can be automated to a large extent with LLMs. Products or features that didn't bring much risk to an organization (and hence didn't have any security activity performed on them) before can now be security reviewed with LLMs increasing the coverage of an appsec team. Artifacts or the data gathered from the security activities can be used to train LLMs to become more accurate and effective over time.
With frameworks like the Retrieval Augmented Generation (RAG), LLMs can be made to understand and generate more accurate and contextually relevant text / recommendations. We can finally build a Security Oracle that can answer questions, provide recommendations, and even generate artifacts - all by using the organization's best practices, policies and other bespoke documentation. SecurityGPT anyone?
As these technologies continue to evolve, I believe we will see a move towards integrating LLMs and AI agents into our daily workflows to help us identify, prioritize, and remediate vulnerabilities more efficiently. And, this is just the beginning.
In order to evaluate if such a future is plausible, I went down a rabbit hole for the past few weeks to see what I can build and how quickly I can build it. In this post, I am going to share some of the experiments I did and what I learned along the way.
Scaling AppSec Activities using LLMs
If you'd rather watch a presentation where I go over some of these ideas, you can find it below. If this topic is of interest to you, I'd recommend continue reading as this blog post goes into more detail about the POCs and the learnings from them.
High Level Overview
Let's start with a high level overview of how we can scale AppSec activities using LLMs.
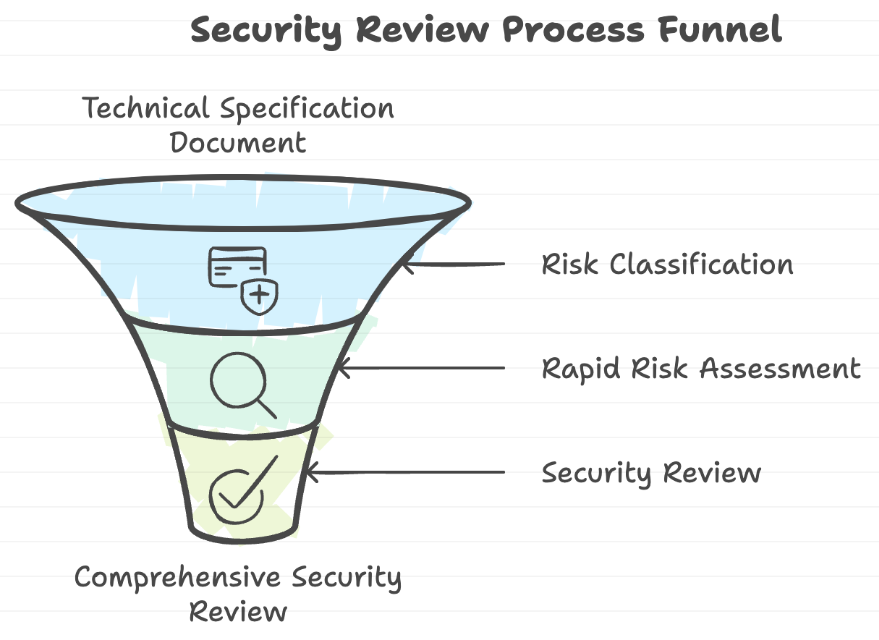
We are going to start by taking a technical specification document (for a new feature) as an input to a security review workflow and perform 3 activities on it:
-
Risk Classification - This step classifies the risk based on the provided technical specification and assigns a risk score based on the organization's risk framework and data classification. This could be modified depending on the organization's needs.
-
Rapid Risk Assessment - Using Mozilla's RRA guide as the framework, this step performs a rapid risk assessment of the feature. It outputs a risk assessment report that contains the risk, impact, likelihood and mitigation for any security gaps that were identified. This could also be modified to use a different framework if needed, depending on the organization's needs.
-
Security Review - This step performs 2 kinds of security reviews:
-
one by simply providing the instructions in natural language focussing on things like Authentication, Authorization, Encryption, Input Validation and Observability. You can think of this like a light weight design review covering the basics.
-
one by querying an in-memory RAG assistant. You can think of this like passing the technical specification to an expert AppSec AI assistant (who is knowledgeable about the org's best practices and policies) who can review the design and provide recommendations.
-
Once the activities are complete, the outputs from each step is then consolidated and a final report is displayed to the user.
Also, all of the above activities are customizable in the sense that they are all prompts at the end of the day describing to the LLM - what needs to happen, in what order, what parameters to use, what artifacts to produce, etc.
NOTE - The technical specification document is a fictional one and does not represent any real product. It was intentionally created to have some security issues to highlight the capabilities of the LLM review workflow.
The 3 best practices documents are also fictional and do not represent any real organization. The in-memory RAG assistant is created (using OpenAI's Assistants API) by vectorizing these documents and attaching them to it in memory. For real world use cases, the RAG assistant could be its own service/system and does not have to be in memory.
You can find all the artifacts used in this POC here.
Data Flow
Next, let's take a look at a data flow diagram for the POC. These are also available in the repo here
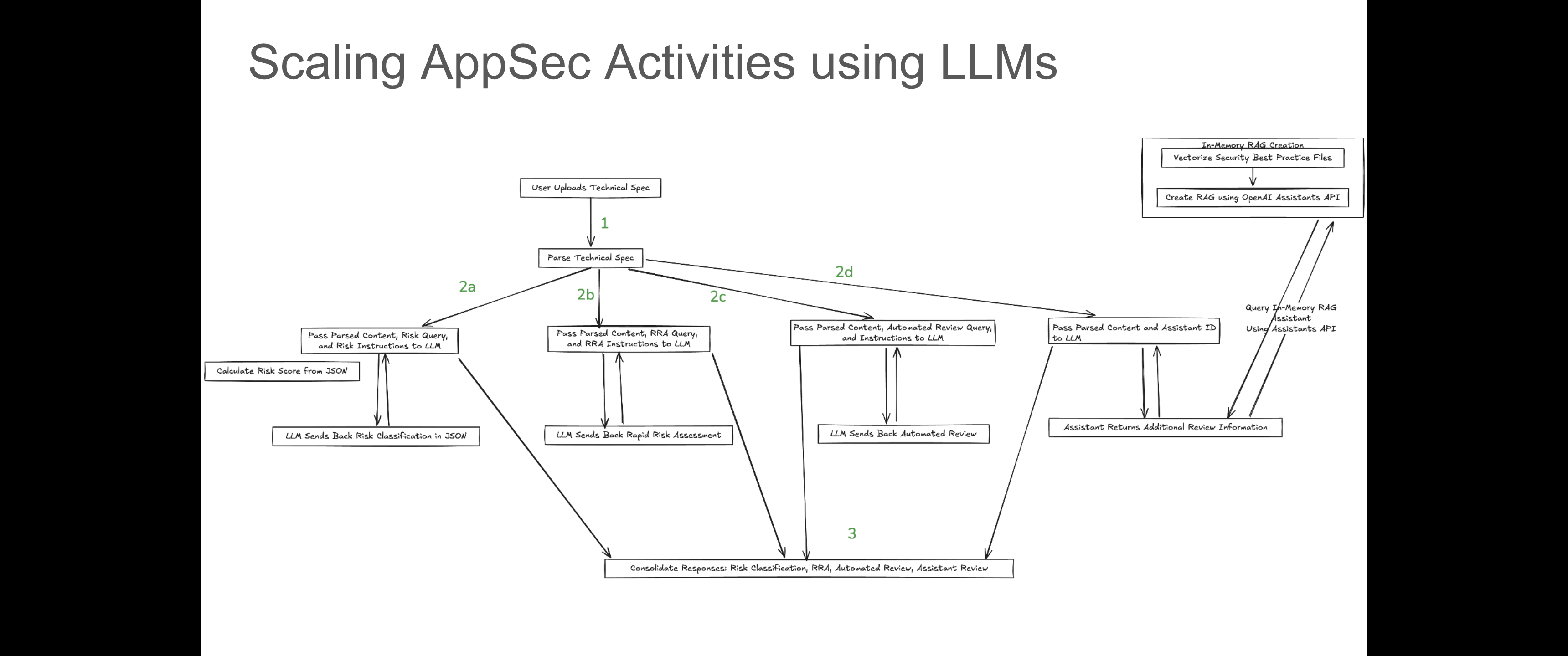
In the above diagram:
-
Step 1 is the intake process where the technical specification document is provided as an input by an end user. You could perform a few pre-processing steps (like checking for images and transcribing them, as applicable) at this stage before proceeding.
-
Steps 2a-2d are the activities performed automatically on the tech spec:
- 2a is the risk classification step
- 2b is the rapid risk assessment step
- 2c is the security review step (without RAG)
- 2d is the security review step (with RAG)
-
Step 3 is when the consolidation of all the outputs happen and the final report is displayed to the user.
The diagram might look a bit overwhelming at first but it is actually quite simple. The workflow initiates on uploading a tech spec (step 1). The tech spec is parsed and the content is passed along with the query and instructions for each security activity.
The query and instructions are nothing but prompts. The 3 things are then sent to the LLM using OpenAI's Chat Completions API. This is essentially what takes place for steps 2a-2c.
Step 2d is implemented using OpenAI's Assistants API which allows us to query the in-memory RAG assistant for security best practices. Some sample code snippets are provided in the Technical Details section below.
Demo
Below is a quick demo of the above POC. It doesn't have an audio but you can see that I start the workflow by running the Streamlit app locally, which then creates the in-memory RAG assistant using the 3 best practices documents. It then asks the user to upload a tech spec. Once the tech spec is uploaded, it starts performing the security activities on it. The workflow completes all the activities and then displays the outcome from each step in the UI itself.
Data Flow (with AI Agents)
I wanted to go one step beyond and see if we can build a similar system, but with AI agents using some kind of an Agentic framework. In my case, I wanted to experiment with OpenAI's Swarm which was open sourced recently. AI Agents are LLMs that can perform a series of steps to achieve a goal. You can write functions and attach them to an agent and the agent will be able to call the functions to perform the task. We can then build a system that has multiple agents working together to achieve a goal such as performing a security review on a technical specification document. The data flow for such a system could look like below:
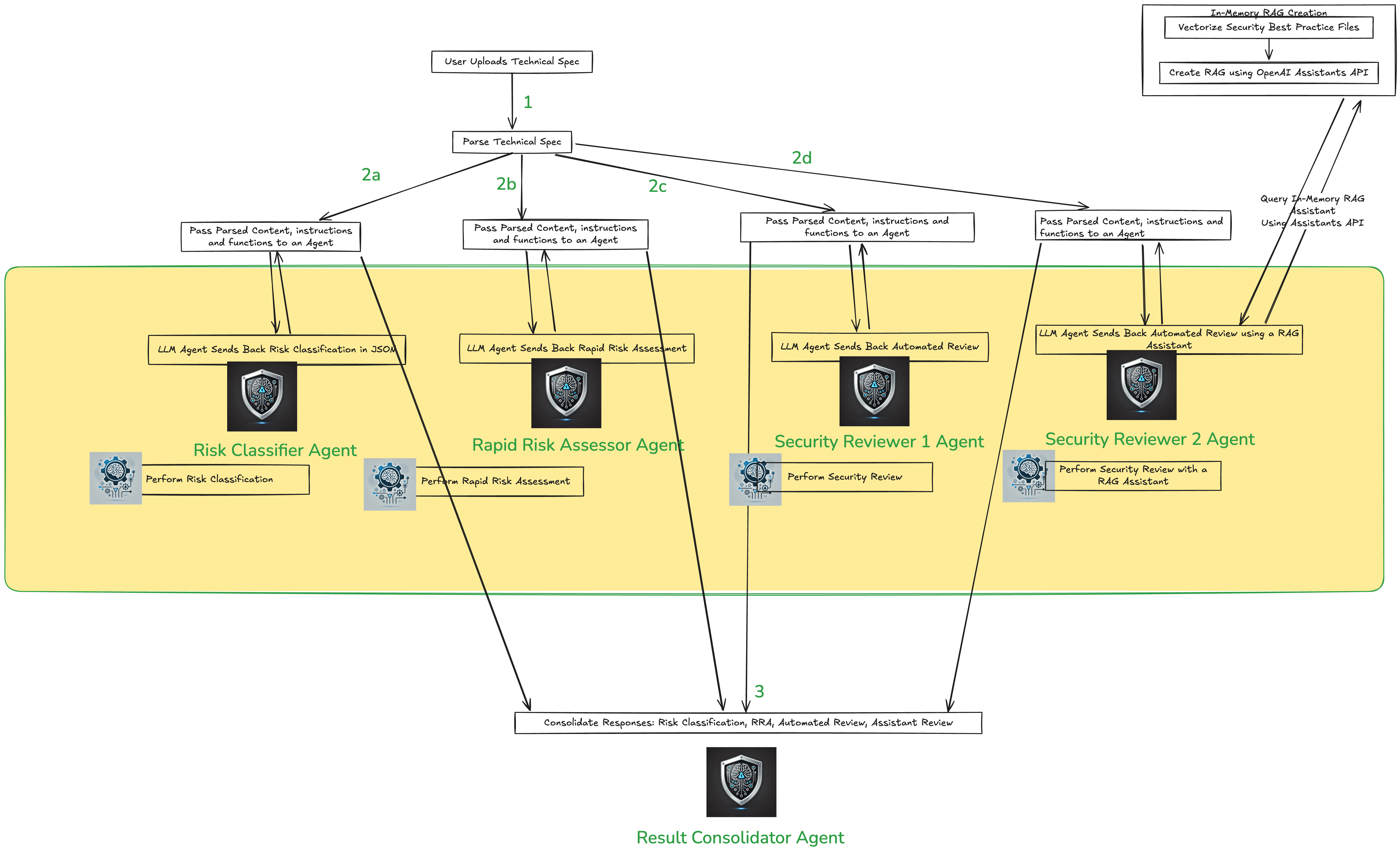
In the above diagram:
-
All steps from the previous data flow are the same. The only difference is that each step is now performed by an AI agent. And, each agent is attached with the relevant functions to perform the task. For example, the
Risk Classifieragent is attached with theperform_risk_classificationfunction. -
All agents are orchestrated and defined using the OpenAI Swarm client. And, individual results from each agent are sent to a
Result Consolidatoragent which consolidates the results and displays the final report to the user.
Demo (with Agents)
And, if the above diagram looks a bit overwhelming, here is a quick demo of the POC with agents. You will notice that the outcome from both the POCs are very similar. This shows that no matter what approach you take - whether with Agents or not - the core idea remains the same i.e. to get LLMs to augment appsec engineers. The question that would be worth exploring is - do you really need agents to achieve this?
Technical Details
If you are not interested in the technical details, you can skip this section and jump to the Learnings and Observations section.
The tech stack used for both the POCs is:
-
OpenAI - Chat Completions API for performing the security activities and Assistants API for creating and querying the RAG assistant. The RAG assistant was created in-memory.
-
Streamlit - for the UI
-
Swarm - The Agentic framework used for building the POC with AI agents.
Below are some snippets of the code used for the POCs:
Creating the RAG Assistant
The code that creates this assistant (in memory) every time the app is run is below. The
GUIDES_DIRis the directory where the security best practices documents are stored.
assistant = client.beta.assistants.create( name="Security Review Assistant", instructions="You are an expert security engineer. Use your knowledge base to answer questions about security best practices.", model=MODEL, tools=[{"type": "file_search"}], ) st.write(f"Assistant created: {assistant.id}") # Create a vector store caled "Security Best Practices" vector_store = client.beta.vector_stores.create(name="Security Best Practices") # Ready the files for upload to OpenAI guides_dir = GUIDES_DIR file_paths = glob.glob(f"{guides_dir}/*.pdf") file_streams = [open(path, "rb") for path in file_paths] # Use the upload and poll SDK helper to upload the files, add them to the vector store, # and poll the status of the file batch for completion. file_batch = client.beta.vector_stores.file_batches.upload_and_poll( vector_store_id=vector_store.id, files=file_streams ) st.write(f"File batch status: {file_batch.status}") st.write(f"File batch file counts: {file_batch.file_counts}") assistant = client.beta.assistants.update( assistant_id=assistant.id, tool_resources={"file_search": {"vector_store_ids": [vector_store.id]}}, )
Using the Chat Completions API to perform the security activities (without RAG)
The function that performs the security activities (without RAG) is below. The
llm_paramsis a dictionary that contains the model, temperature, etc.
def generate_from_query(query: str, context: str, instructions: str) -> str: # Ensure the OpenAI API key is set in your environment variables # Construct the messages for the chat completion messages = [ {"role": "system", "content": instructions}, {"role": "user", "content": f"Context: {context}\n\nQuery: {query}"} ] # Make the API call response = client.chat.completions.create(model=llm_params["model"], messages=messages, temperature=llm_params["temperature"]) # Extract and return the content return response.choices[0].message.content
Using the Assistants API to perform the security review (with RAG)
The function that performs the security review (with RAG) is below. The
assistant_idis the ID of the RAG assistant created earlier.
def assistant_query(assistant_name, content): query_string = f""" You are an application security engineer working for an organization. Your job is to parse the tech spec provided and perform a security review on it by comparing it against the security best practices that exists in your knowledgebase. The following things need to be considered for the security review: - authentication - authorization - input validation - encryption - logging - monitoring and alerting While you are reviewing the spec for the above criteria, if you come across any specific best practices mentioned in your knowledgebase for a given criteria, please highlight those as well. The contents of the spec are between the "<START-SPEC>" and "<END-SPEC>" tags, not including the tags themselves. <START-SPEC> {content} <END-SPEC> After you've reviewed it, please provide the following in your response: 1. Give a high level summary of the content as well as what you are asked to do. 2. Against each of the above criteria (authentication, authorization, input validation, encryption, logging, monitoring and alerting), perform a security review highlighting any security best practices that are already proposed and any potential recommendations to improve the security of the system. 3. Please avoid giving generic recommendations unless you can give those recommendations with actual content mentioned in the spec put into perspective. 4. If there are any specific security best practices mentioned in your knowledgebase for a given criteria, please highlight those as well. """ thread = client.beta.threads.create() message = client.beta.threads.messages.create( thread_id=thread.id, role="user", content=query_string ) run = client.beta.threads.runs.create( thread_id=thread.id, assistant_id=assistant_name, ) while run.status != "completed": run = client.beta.threads.runs.retrieve( thread_id=thread.id, run_id=run.id ) time.sleep(1) # Wait for 1 second before checking again messages = client.beta.threads.messages.list(thread_id=thread.id) return(messages.data[0].content[0].text.value)
Agentic Code
Below is an example of how we can use the Swarm API to create the agents and orchestrate the workflow.
- First, we parse the technical specification document to extract the content. Let's say we store the content in a variable called
context_str.
context_variables = {"context": context_str}
- Next, we invoke the
Risk Classifieragent
# Run risk classifier response = swarm_client.run( agent=risk_classifier, messages=[{"role": "user", "content": "Perform risk classification and calculate a risk score on the provided context"}], context_variables=context_variables, ) risk_classification_response = response.messages[-1]["content"]
- The
Risk Classifieragent is defined as below.
risk_classifier = Agent( name="Risk Classifier", instructions=risk_classifier_instructions, functions=[perform_risk_classification, transfer_to_result_consolidator], )
- The
risk_classifier_instructionsis the instructions provided to theRisk Classifieragent.
def risk_classifier_instructions(context_variables): context = context_variables["context"] instructions_str = f""" Your purpose is to classify the risk level of a project and calculate a risk score based on the provided context. You will do this by executing the perform_risk_classification function. You will then only send the output from the perform_risk_classification function to the result consolidator. The context to perform the risk classification on is between the "<START-SPEC>" and "<END-SPEC>" tags, not including the tags themselves. <START-SPEC> {context} <END-SPEC> """ return instructions_str
Learnings and Observations
As I was experimenting with the POCs, I came across a few learnings and observations:
-
Summary of large corpus of text - If not the security review itself, LLMs do a good job at summarizing large chunks of text. You can easily extract the important bits by simply modifying the prompt.
-
Works well with a format / structure - If technical specifications are written in a standard format, LLMs do a good job at parsing them. If they are not, the results are not as good.
-
Augmenting security engineers - The above POCs are great at augmenting security engineers, not replacing them. They are no where close to being able to replace a security engineer.
-
Image parsing is not trivial - This is a big one. It almost feels like parsing different architecture diagrams and transcribing the main data flows and components in readable text should be a service in itself. I tried to solve this problem while the tech specs were being parsed and I went down a rabbithole I wish I hadn't.
-
Using the RAG Assistant produced more detailed results - In my experimentation, I found out that the security review step using the RAG assistant produced the most relevant outcome that I'd like to see as an appsec engineer. Also, writing prompts is a big piece of the puzzle. I haven't come across a specific format of writing prompts that will cover all use cases. I believe this is an area of research and a lot of work is being done in this area. I also believe this is where building some kind of an evaluation framework for LLMs will be useful.
-
Will only improve with newer models - The POCs discussed above were implemented using GPT-4o. I am sure the results will be better with newer models. It will also help to understand the chain of reasoning of the LLM.
-
Building an internal RAG assistant is easier said than done - Access Control is a nightmare, specially when it comes to RAG based systems. Integrating it with existing systems could be challenging as well. There is some research happening around this area. I found the Securing LLM Backed Systems: Esential Authorization Practices paper super helpful.
-
Improving the workflow initiation - The POCs above concern a user uploading a tech spec and then performing a bunch of security activities on it. It is still reactive in a way. It would be interesting to automate this part as well so that the place where these tech specs are created in the first place (Let's say Google Docs for example) could trigger some kind of an event or a workflow that would send the tech spec through the LLM review workflow. This would ensure that the workflow is at least triggered automatically without any human intervention.
-
AI Agents need to be dealt with carefully - Some parts of an agentic framework rely on the fact that Agents have the autonomy to perform tasks depending upon their understanding of the problem statement and the provided context and instructions. The outcomes are not super controlled. This could be good or bad depending on the use case. As much as cross collaboration agents are exciting, building some kind of a guardrail system with defined inputs and outputs could help bring some sanity to the AI Agents.
Conclusion
In conclusion, the inefficiencies and scalability challenges of manual Application Security (AppSec) processes are becoming increasingly untenable in today's fast-paced digital environment. Large Language Models (LLMs) offer a viable solution to automate and enhance these processes, bringing unprecedented efficiency and effectiveness to AppSec activities. By embracing Generative AI and LLMs, we can revolutionize the way we approach security, opening doors to innovations previously thought unattainable.
However, it's important to recognize that not every facet of security will require AI agents; human expertise and judgment remain invaluable assets. The field is largely a greenfield, presenting immense opportunities for improvement and innovation across the security industry. Now is the time to seize these opportunities, leveraging both advanced technologies and human insights to build a more secure future.
If you've made it this far, thank you for reading! I hope you found this interesting and I would love to hear your thoughts on this. If you are interested in building something similar and would like to collaborate, feel free to reach out.